Seven steps to move a DevOps team into the ML and AI world
Artificial intelligence and machine learning can bring a lot to the software development and deployment table. But patience and experimentation will be key to make it work in an enterprise.
Nobody questions the potential for machine learning and artificial intelligence to revolutionize DevOps productivity and business efficiency as a whole, really. An invisible hand, however, keeps organizations from seeing ML and AI to their full potential.
There are seven basic rules to implement ML and AI in real-life DevOps situations. Done right, ML/AI and DevOps can turn enterprises into digital attackers that release higher-quality software faster and at lower cost.
To release on time and within budget, there is little to no room for error when it comes to the choice of the technology path. ML- and AI-driven solutions often promise much better end results. So should a DevOps team go slowly and safely, or jump all in?
Rule #1: Start with canned APIs
Encourage and enable development teams to get creative with canned API offerings like AWS Rekognition, Watson, Google or Azure. These APIs allow developers to incorporate robust ML/AI capabilities into their software without the need to create, deploy and train their own models. Development teams can then easily add capabilities such as voice-to-text, image categorization or text-on-image recognition. Keep in mind that these ML and AI services are powerful but only optimized for general use.
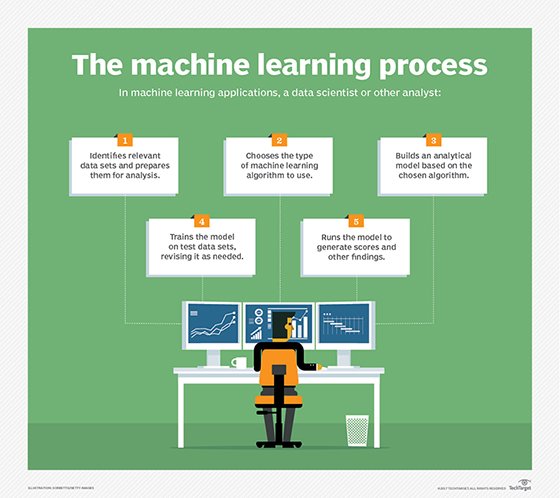
Machine learning can give a team the data to do DevOps right.
Rule #2: Make it modular
For further expansion, developers need to create and share artifacts of useful ML/AI APIs. In a next step, teams can share entire pre-trained models -- based on AWS SageMaker or Azure Machine Learning -- as artifacts. The entire development organization can now benefit from successful ML/AI model deployments and individual teams can further enhance the artifact and then apply it to additional use cases.
Rule #3: Use a parallel pipeline to prevent disruption
Despite all the hype around ML and AI, it is critical to remember this discipline is still in a stage that relies heavily on experimentation. So a team that relies on ML/AI models performing in step with project capabilities must practice contingency planning as well. Teams should add ML/AI in a gradual manner to avoid significant project delays in case of problems. This seemingly cautious approach is vital if you plan to apply ML and AI to company-specific and mission-critical challenges.
Rule #4: Offer pre-trained models for easy proof of concept
Done right, ML/AI and DevOps can turn enterprises into digital attackers that release higher-quality software faster and at lower cost.
Well-documented, pre-trained models can dramatically reduce the threshold for ML and AI adoption. Imagine you want to build an app that will recognize a dog breed from a user's picture. To prove your concept, you can first assemble a pre-trained model for general image recognition. Chances are that this general model will be able to at least recognize a few common types of dogs. Then, it is reasonable to conclude that if your app works for German shepherds and dachshunds, it is worth the time to further train the model and upload images of all the other breeds.
Rule #5: Require and reward metrics
The value of ML/AI-driven solutions often becomes clear once the software is in use and it turns out that it can complete certain tasks at higher quality, with more flexibility and much quicker than the traditional coding approach. ML and AI advocates, then, need to translate these facts into performance or customer satisfaction metrics for fellow developers. Put the most significant success stories into the corporate newsletter and award the respective team with a visible trophy.
Rule #6: Don't mind the gap -- bridge it with public data
One of the key challenges to ML and AI adoption and success is finding a sufficient amount of initial training data. This can be difficult, simply because no one logged this historic data or it's somehow not available. In these frequent cases, you can often find public data sets through providers such as Kaggle. This can bridge data gaps with information, while not specific to your project, but that fills in missing areas to make your project viable.
Rule #7: Use ML and AI like a Swiss army knife
Software developers should always have some extra time to broaden their horizons, especially when it comes to use cases for ML/AI. Organizations should encourage this through easy access to ML/AI sandboxes and general-purpose APIs, without the formalities that come with the corporate procurement process.
What comes next?
We need vendors to make ML and AI more snackable than even what AWS SageMaker or Azure Machine Learning Studio offer. While the launch of both made ML/AI more accessible to standard full-stack developers, there still is much ground to cover on the journey toward mainstream machine learning.
What I would like to see next is a much more transparent and better led training process. I would also like to see a visual interface that scores the quality of my data set and recommends the inclusion, exclusion or transformation of data columns. I want to see the immediate impact -- positive or negative -- of additional training materials.